


我在《小公司如何应对大数据热潮?借助第三方服务,或者逆势而为抛开数据业务架构》中说过,由于小型和普通规模的公司收集、存储、组织、分析并应用大数据的成本往往非常高,所以可以考虑利用第三方的数据采集、分析服务,并介绍了一些海外的成熟的第三方数据服务提供商——帮助电商提供个性化网上购物体验的RichRelevance、个性化和数字市场营销优化服务提供商Baynote、为广告商提供数据和分析的eXelate,以及数据拍卖平台BlueKai等,可惜对于大部分中国企业而言,它们似乎都太过遥远,但实际上,在中国也有一些具备实力的第三方服务商,百分点就是其中的佼佼者,他们主要解决两个问题:打破传统网站只拥有自身数据的局限性、降低大数据技术的应用门槛。
百分点的模式很容易理解:当消费者登陆电商、阅读、音乐后,会产生一系列的浏览、分享、收藏和购买行为,这些行为与用户电脑上的Cookie(某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据)是相对应的。这些网站会将用户行为和Cookie提交到百分点,这样百分点就汇集了由不同网站收集的同一个Cookie对应的各种消费行为,为每个Cookie建立一个丰富的数据模型,再依靠这个数据模型在每个网站中向Cookie做合适的产品、文章、音乐推荐。我认为可以简单的理解为:利用类似众包的方式得到足够多的数据量,在对这些数据进行处理——如今百分点已经拥有1.6亿个Cookie所对应的消费行为数据。
百分点的首席科学家周涛告诉我,用来做推荐的并不单单是用户的行为数据,还包括从各类门户、垂直网站等获取到的对商品、资讯等的侧面信息,例如商品评价、价格走向等,是对核心数据的进一步丰富和补充,同还会利用IP库、行政区划、商圈、天气等信息为数据的组织和应用提供多维度的辅助。
周涛向我介绍了整个推荐引擎的架构,如图所示,它由场景引擎、规则引擎、算法引擎和展示引擎四部分组成。
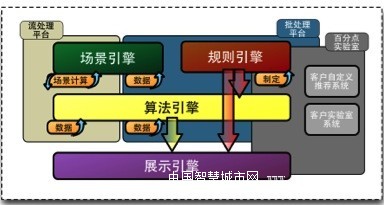
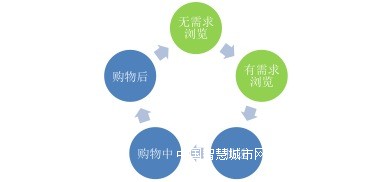
其中场景引擎是整个架构的核心,利用场景引擎,可以将用户意图和意图强弱做详细的判别:无需求的随意浏览、有需求的浏览,同品类中的挑选、加入购物车/搜藏以及购买,这些不同的意图在用户的购物行为中所占的权重不同,显然它们之间的关系是购买>收藏>挑选>有需求浏览>随意浏览。
规则引擎是根据商家对不同商品的出售意愿的强烈程度进行不同的权重设计。简单地说,场景引擎计算用户的意图,规则引擎根据用户意图向算法引擎请求合适的推荐数据,向展示引擎请求合适的展示方式,最终将数据展示在用户面前。
我们知道,互联网上的用户行为每时每刻都在发生变化,所以对海量数据的处理除了“精准”之外,还要做到“快”。例如Facebook就能做到7秒内更新一次处理的结果,百度SEM的投放大概为6小时更新一次。百分点的CEO柏林森说,为了做到更快地处理,需要从架构和算法上进行调整,把数据拆开计算,再把结果合并起来。目前百分点的主要客户是一些电商网站、个性化阅读产品、个性化音乐产品,他们也开始为一些媒体提供推荐引擎服务,帮助读者看到他们最感兴趣的内容。
